
Red Hat OpenShift Data Science:AI/ML 向けのクラウドサービス
インテリジェント・アプリケーションをより迅速に採用
人工知能 (AI)、機械学習 (ML)、ディープラーニング (DL) は、多種多様な企業や業界におけるアプリケーションのモダナイゼーションの取り組みに大きな影響を与えています。さまざまな組織で、データから戦略的価値と新たな知見を導き出し、インテリジェントなクラウドネイティブ・アプリケーションと DevOps 手法の使用拡大を促進することが必要とされています。このすばらしい新世界は複雑なものになるでしょうし、開発者からデータサイエンティスト、運用スタッフに至るまで、あらゆる人に影響を及ぼします。従来のアプローチでは次のような課題が生じる可能性があります。
- 急速に進化するツールやアプリケーションサービスを最新かつ一貫した状態に保つことから、グラフィック・プロセッシング・ユニット (GPU) などのハードウェアリソースのプロビジョニング、インテリジェント・アプリケーションのスケーリングなど、開始するのが非常に困難な場合があります。
- 一般的なクラウド・プラットフォームは、大規模で魅力的な統合環境とツールセットを提供しますが、ツールチェーンに制限があり、デプロイオプションが限られているため、ユーザーを効果的に囲い込むことになります。
- アプリケーション開発者とデータサイエンティストが異なるプラットフォームを使用する場合、コラボレーションが複雑になり、開発スピードが遅くなります。
- インテリジェント・アプリケーションの大規模なデプロイは、特に開発プラットフォームと運用プラットフォームが個別に関与している場合には困難になることがあります。
マネージド・クラウドサービスのオファリングである Red Hat® OpenShift® Data Science は、データサイエンティストと開発者に対し、インテリジェント・アプリケーションの構築とデプロイに対応する強力な AI/ML プラットフォームを提供します。組織にとっては、選択したツールによる実験、共通プラットフォームでのコラボレーション、市場投入時間の短縮が可能になり、これらすべてを 1 つの共通プラットフォーム内で行うことができます。OpenShift Data Science は、データサイエンティストや開発者が求めるセルフサービス環境と、エンタープライズ IT が求める信頼性を兼ね備えています。
信頼できる基盤を使用することで、ライフサイクル全体を通じて摩擦が軽減されます。OpenShift Data Science は、堅牢なプラットフォーム、人気のある認定ツールから成る広範なエコシステム、モデルをプロダクションにデプロイするための使い慣れたワークフローを提供します。これらの利点により、チーム間の摩擦が少ないコラボレーションが可能になり、インテリジェント・アプリケーションの市場投入を効率化でき、結果的にビジネスに大きな価値がもたらされます。
迅速な開発、トレーニング、テスト、デプロイ
OpenShift Data Science は、コミュニティの Open Data Hub プロジェクトと Operate First に基づいています。Open Data Hub は、Apache Kafka や Kubeflow などのアップストリームの取り組みを用いて Red Hat OpenShift 上の AI/ML プラットフォームを実証します。Operate First は、オープンソースの概念を運用に取り入れ、開発者と運用者が連携してプロプライエタリーのロックインを回避しながら優れた運用を実現できるようにします。OpenShift Data Science は、フルサポート付きのクラウドサービスで一部の Open Data Hub ツールを提供します。Amazon Web Services (AWS) で管理され、任意で独立系ソフトウェアベンダー (ISV) のオファリングも利用できます。
選択したツールによる実験
データサイエンティストは、OpenShift Data Science を使用することで、ビジネスに知見をもたらす新たな方法を実験し、発見できます。フルマネージドのクラウドサービスであり、データサイエンティストは、機械学習モデルをデプロイする前に開発し、トレーニングし、テストすることができます。チームは、統合エクスペリエンスにおいて提供される高度なツールにアクセスできます。データサイエンティストは、使い慣れたツールを使用したり、拡大し続けるテクノロジー・パートナー・エコシステムにアクセスして AI/ML の専門知識を深めたりすることができます。所定のツールチェーンに煩わされることはありません。IT 部門が必要なリソースをプロビジョニングするのを待つのではなく、IT チケットではなくクリックだけでオンデマンドでインフラストラクチャを取得できます。
共通プラットフォームでのコラボレーション
OpenShift Data Science は、機械学習ワークロードと開発ワークフロー向けに設計されたオープンソース・アーキテクチャに基づいて構築されています。これにより、データサイエンスと DevOps の間のギャップが狭まり、プロダクションに移行する際の引き継ぎ時の面倒が軽減されます。データサイエンティストは、Jupyter ノートブックでリアルタイムで連携します。開発者にとっては、コンテナ対応モデルをインテリジェント・アプリケーションに統合する際の手間が軽減されます。IT 部門は不正なクラウド・プラットフォーム・アカウントを追跡する必要がないため、ガバナンスについて気にかけることが少なくなります。
インテリジェント・アプリケーションの市場投入時間の短縮
OpenShift Data Science は、一貫した共有プラットフォーム上でより高速に、初期のパイロットからの機械学習モデルをインテリジェント・アプリケーションに導入します。データサイエンティストはツールを選択し、セルフサービス・インフラストラクチャにアクセスすることで、すぐに開始できます。このサービスは、ソフトウェア・パートナー・エコシステムを通じて、機械学習ライフサイクルのあらゆる段階をより深い AI 機能と結び付け、AI/ML の専門知識を備えた広範な認定ツールを提供します。組織はモデルをハイブリッドクラウド環境にデプロイでき、商用クラウドに縛られることなく、組織にとって必要な場所でワークロードを実行できる柔軟性が得られます。
OpenShift Data Science
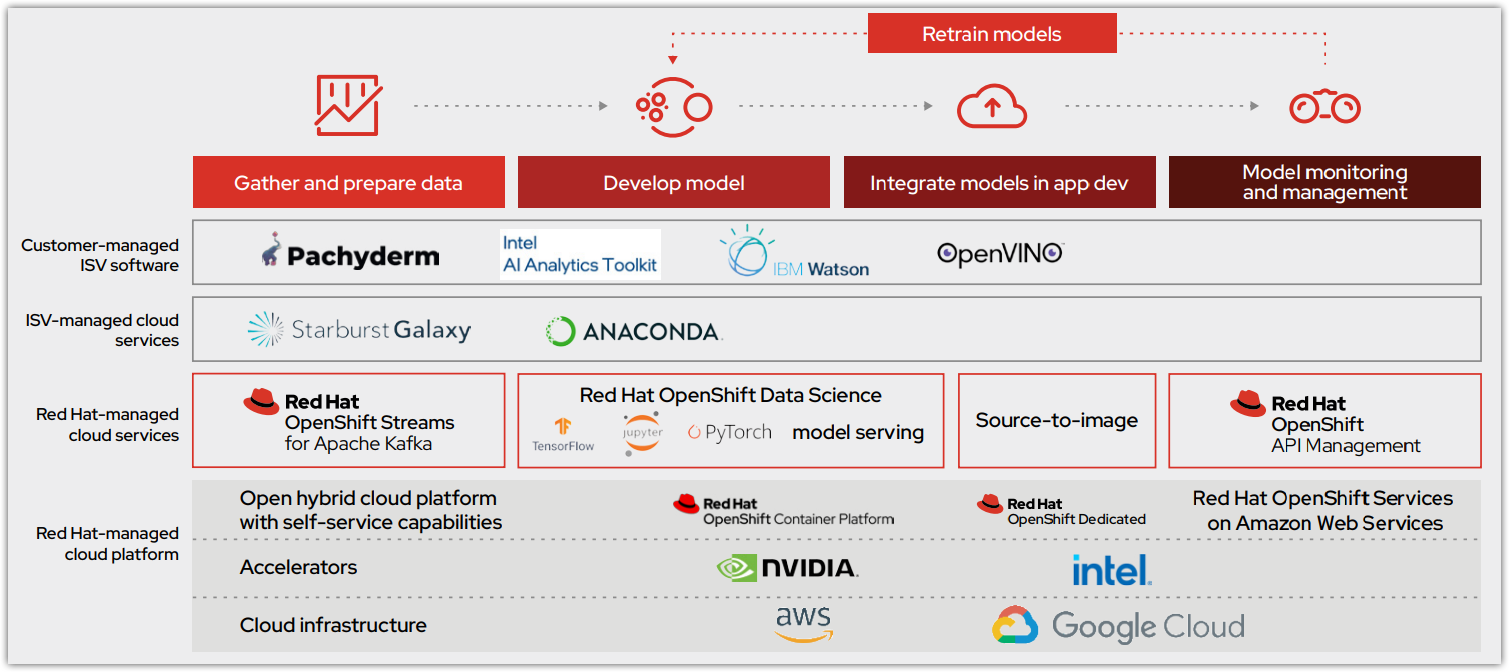
図 1 は、モデル運用ライフサイクルが共通プラットフォームとしての OpenShift Data Science の初期オファリングとどのように統合されるかを示しています。このクラウドサービスは、Red Hat OpenShift Dedicated (AWS 上) および Red Hat OpenShift Service on AWS で利用できます。これは、コアとなるデータ・サイエンス・ワークフローを Red Hat マネージドサービスとして提供するものであり、ISV 認定ソフトウェアを通じて機能とコラボレーションを向上することができます。モデルは OpenShift クラウドサービスでホストされるか、インテリジェント・アプリケーションに統合するためにエクスポートされます。
ハイライト
- インフラストラクチャを気にすることなく、任意のツールを使用して開発できる
- データサイエンティスト、開発者、IT 運用を統合する共通プラットフォームで、摩擦を軽減し、連携できる
- インテリジェント・アプリケーションの提供を加速し、市場投入時間を短縮できる
- 巨大なパートナーエコシステムからアプリケーションやサービスを選択できるようにすることで、データサイエンティストを強化できる
OpenShift Data Science がもたらす中心的なツールと機能が強固な基盤を提供します。
- Jupyter ノートブック:データサイエンティストは、TensorFlow や PyTorch など、中核となる AI/ML ライブラリおよびフレームワークにアクセスし、JupyterLab で探索的データサイエンスを実施できます。
- Source-to-Image (S2I):モデルは S2I 経由でエンドポイントとして公開してインテリジェント・アプリケーションに統合でき、ソースノートブックの変更に基づいて再構築および再デプロイできます。
- 最適化された推論: ディープラーニングモデルを最適化された推論エンジンに変換して、実験を加速できます。
Red Hat が Tensorflow および PyTorch 用の Jupyter ノートブックイメージをサービスの一部として提供するため、チームがゼロから始める必要はなく、強力なテクノロジーを簡単に採用できます。一貫性と柔軟性を確保するために、Jupyter Spawner は組織のカスタムイメージをデータサイエンスチームに導入し、優先ライブラリ、ツール、言語を組み込むことができます。このサービスには、JupyterLab への Git プラグインも含まれているため、JupyterLab インタフェースから直接 Git と統合する時間が短縮されます。他にも一般的な分析パッケージがサービスの一部として提供されるため、運用が単純化され、Pandas、scikit-learn、NumPy など、組織のプロジェクトに適切なツールを使用して簡単に開始することができます。
Red Hat は、マネージド・クラウドサービスとして、基盤となる OpenShift アプリケーション・プラットフォームと OpenShift Data Science サービスのための SRE (サイト信頼性エンジニアリング) サポートを提供します。このサポートにより、お客様は基盤のプラットフォームではなく、ビジネス分析に集中できるようになります。Red Hat は、基盤となる Red Hat OpenShift マネージド・クラウドサービス環境を含め、Red Hat OpenShift Data Science サービスの高可用性を維持します。アップデート、アップグレード、互換性はすべてサービスの一部として管理されるため、複雑になる可能性がある分析ツール間の互換性マトリックスを追跡する必要がなくなります。
モデルのライフサイクル全体に対応するツール
OpenShift Data Science は、組織がモデルを正常にデプロイしてプロダクションに移行できるようにするためのサービスとソフトウェアを提供します (図 2)。このプロセスは、OpenShift Data Science に加えて Red Hat OpenShift API Management とも統合されています。

Red Hat OpenShift Data Sciences ダッシュボードは導入を容易にし、すべてのアプリケーションとドキュメントを検出してそれらにアクセスするための中心的な場所を提供します。スマート・スタート・チュートリアルは、一般的なコンポーネントと統合パートナーソフトウェアに関するベストプラクティスのガイダンスを提供します。ダッシュボードから直接利用できるため、データサイエンティストがより迅速に学習し、開始することができます。以下のセクションでは、Red Hat OpenShift Data Science に含まれる主要な分析ツールについて説明します。
Starburst
Starburst は、組織のチームがビジネス機能を改善するためにデータを迅速かつ容易に活用できるようにすることで、分析を加速します。Starburst はセルフマネージド製品またはフルマネージドサービスとして提供され、データアクセスを民主化し、データ利用者により包括的な知見を提供します。Starburst は、プレミア超並列処理 (MPP) SQL エンジンであるオープンソースの Trino (旧名 PrestoSQL) に基づいて構築されています。Trino の専門家と Presto の作成者によって構築および運用されている Starburst を使用すると、組織のデータを移動することなく、さまざまなデータセットがどこにあっても自由に調べることができます。
Starburst は、Red Hat OpenShift が提供するスケーラブルなクラウドストレージとコンピューティングのサービスと統合し、すべてのエンタープライズデータをクエリする、より安定したセキュリティ重視の効率的かつコスト効率の高い方法を提供します。そのメリットには以下のようなものがあります。
- 自動化: Starburst および Red Hat OpenShift オペレーターは、クラスタの自動設定、自動チューニング、自動管理を提供します。
- 高可用性と適切なスケールダウン: Red Hat OpenShift ロードバランサーは、Trino コーディネーターなどのサービスを常時オンの状態に保つことができます。
- 弾力性に優れたスケーラビリティ:Red Hat OpenShift は、クエリの負荷に基づいて Trino ワーカークラスタを自動的にスケーリングできます。

Anaconda Commercial Edition
Anaconda Commercial Edition は、Jupyter プロジェクトで使用する広範なデータ・サイエンス・パッケージへの厳選されたアクセスを提供します。また、事前に構築済みの Jupyter イメージを Red Hat OpenShift Data Sciences ダッシュボードから直接利用できます。Anaconda Commercial Edition を使用すると、商業利用向けに最適化された、世界で最も人気のあるオープンソースパッケージの配布および管理エクスペリエンスにアクセスできます。これには、以下が含まれます。
- Anaconda のプレミアムリポジトリにある、Anaconda が厳選した 7,500 以上のデータサイエンスと ML パッケージを含むオープンソースのイノベーション。
- データサイエンスや ML パイプラインから脆弱性や信頼性の低いソフトウェアを排除するのに役立つ、Conda 署名検証などのコンテンツ信頼機能。
- プロダクション・ワークフローで利用できるアップタイムのサービスレベル契約 (SLA) およびサポートによる信頼性。
- Anaconda の利用規約に基づく商業利用に完全に準拠。
IBM Watson Studio
IBM Watson Studio1 を使用すると、Watson Machine Learning および Watson OpenScale を使用して AI モデルを大規模に構築し、実行し、管理できます。このプラットフォームは、PyTorch、TensorFlow、scikit-learn などのオープンソース・フレームワークと IBM およびそのエコシステムツールを組み合わせて、コードベースのビジュアルデータサイエンスを実現します。このプラットフォームは、Jupyter ノートブック、JupyterLab、コマンドライン・インタフェース (CLI)、Python 言語で動作します。
IBM Watson は AI の運用化を支援し、原則から実践への信頼を高めます。透明性のあるプロセスにより、AI 主導の意思決定に関する知見が得られます。IBM Watson は、高度に規制された業界においてデータのプライバシー、コンプライアンス、セキュリティを実現し、AI の責任ある使用を促進するオープンで多様なエコシステムをサポートします。IBM Watson Studio が提供するものは次のとおりです。
- モデルパイプラインの構築、データの準備とモデルタイプの選択、モデルパイプラインの生成とランク付けを自動的に行う AutoAI と AutoML。
- グラフィックス・フロー・エディターでデータをクレンジングおよび形成する高度なデータリファイナリー。
- データを迅速に準備し、視覚的にモデルを開発する IBM SPSS Modeler を介した統合ビジュアルツール。
- 最適化されたパイプラインによって実験を迅速に構築するモデルトレーニングおよび開発。
- 予測モデルと処方モデルを組み合わせるための組み込みの意思決定最適化。
- モデル管理と、品質、公平性、ドリフト指標の監視。
- Python Jupyter Notebook としてのモデルエクスポート。

Pachyderm
組織は、ラップトップでの実験から重要なエンタープライズデプロイまで、あらゆるものを容易にするデータ管理ソリューションを必要としています。Pachyderm により、データサイエンスチームは、自動的なデータバージョン管理が保証するデータリネージュによって、コンテナ化されたデータ駆動型 ML パイプラインを構築および拡張できます。Pachyderm は現実世界のデータサイエンスの問題を解決するように設計されており、チームが再現性を保証しながら ML ライフサイクルを自動化および拡張できるようにするデータ基盤を提供します。Pachyderm には、非構造化データからデータウェアハウス、自然言語処理、動画および画像 ETL、金融サービス、ライフサイエンスなどさまざまなユースケースがあり、以下を提供します。
- すべてのデータ変更を追跡するための高性能の方法を提供する、自動化されたデータバージョン管理。
- コンピューティングコストを削減しながらデータ処理を高速化する、データ駆動型のコンテナ化パイプライン。
- ML ライフサイクルのすべてのアクティビティとアセットに固定レコードを提供する、不変のデータリネージュ。
- 有向非巡回グラフ (DAG) の直感的な視覚化を実現し、デバッグと再現性を支援する Pachyderm Console。
- Pachyderm バージョン管理データへのポイント・アンド・クリック・インタフェース用の Pachyderm の JupyterLab Mount Extension による Jupyter ノートブックのサポート。
- 組織内のさまざまなチームにまたがって Pachyderm を大規模にデプロイおよび管理するための堅牢なツールによるエンタープライズ管理。

NVIDIA が加速するデータサイエンス
スケーラブルなデータ処理、データ分析、機械学習トレーニング、推論はすべて、リソースを大量に消費する計算タスクです。NVIDIA ソフトウェアにより、GPU の並列処理機能を利用して、エンドツーエンドのデータサイエンスのあらゆる側面を高速化することが可能になります。オンプレミスの GPU リソースのスケーリングや、そのリソースを使用するための Kubernetes のプロビジョニングの設定に、データから価値を抽出したいと考えているデータサイエンティストが煩わされることがあってはなりません。
さまざまな組織が、機械学習やその他の多数のサービスに NVIDIA ソリューションをすでに使用しています。OpenShift Data Science は複雑さを軽減して GPU 対応ハードウェアを立ち上げ、リソースを大量に消費するデータサイエンス実験を加速します。OpenShift Data Science を使用すると、NVIDIA GPU を搭載した Amazon Elastic Computing (EC2) インスタンスをオンデマンドで採用し、必要に応じて計算リソースを増減できます。

Intel OpenVINO ツールキット
Intel Distribution の OpenVINO ツールキットは、Intel プラットフォーム上での高性能 DL 推論アプリケーションの開発とデプロイを加速します。このツールキットを使用すると、付属のモデルオプティマイザーとランタイムツールおよび開発ツールを使用して、包括的な AI 推論のビルド、最適化、調整、実行が可能になります。
- ビルド:開発者は Open Model Zoo を使用して、推論の準備ができているオープンソース、事前トレーニング済み、事前最適化済みのモデルを検索したり、独自の DL モデルを使用したりすることができます。
- 最適化:モデルオプティマイザーはモデルを中間表現 (IR) に変換することができ、その結果、ネットワークトポロジーを記述し、モデルの重みとバイアスを含む一組のファイルを生成します。
- デプロイ: 推論エンジンは、複数のプロセッサー、アクセラレーター、および環境上で結果を出力でき、一度書き込めばどこにでもデプロイできるという効率性を備えています。

Intel® AI Analytics Toolkit
Intel AI Analytics Toolkit は、データサイエンティスト、AI 開発者、研究者に、Intel アーキテクチャ上でエンドツーエンドのデータサイエンスおよび分析パイプラインを高速化するための使い慣れた Python ツールとフレームワークを提供します。コンポーネントは oneAPI ライブラリを使用して低レベルのコンピューティングを最適化します。このツールキットは、ML による前処理のパフォーマンスを最大化し、効率的なモデル開発のための相互運用性を提供します。
Intel AI Analytics Toolkit を使用すると、次のことが可能になります。
- Intel XPU 上で高性能の DL トレーニングを提供し、Intel に最適化された TensorFlow および PyTorch 用の DL フレームワーク、事前トレーニング済みモデル、低精度ツールを使用して高速推論を AI 開発ワークフローに統合する。
- Intel 向けに最適化された、コンピューティング集約型の Python パッケージ、Modin、scikit-learn、XGBoost を使用して、データ前処理と ML ワークフローのドロップイン・アクセラレーションを実現する。
- Intel が提供する分析機能と AI 最適化に直接アクセスして、ソフトウェアが中断なく連携できるようにする。
まとめ
OpenShift Data Science を使用することで実験とコラボレーションが可能になり、結果的にインテリジェント・アプリケーションの導入を加速できます。この Red Hat が管理するクラウドベースのアドオンサービスは、データサイエンティストの実験を単純化および高速化し、先進的なコンテナ化 AI/ML プラットフォームと AWS の利便性および拡張性をもたらします。開発者とデータサイエンティスト向けのセルフサービスにより、エンタープライズ IT がすでに使用し完全に信頼しているアプリケーション・プラットフォームでのイノベーションが加速します。競合するアプローチとは異なり、データサイエンティストは制限のないツールチェーンからツールを選択し、任意の制約を課すことなく新たなデータインサイトをもたらすことができます。
IBM Watson Studio および Watson Machine Learning は、IBM の Cloud Pak for Data オファリングに含まれます。
